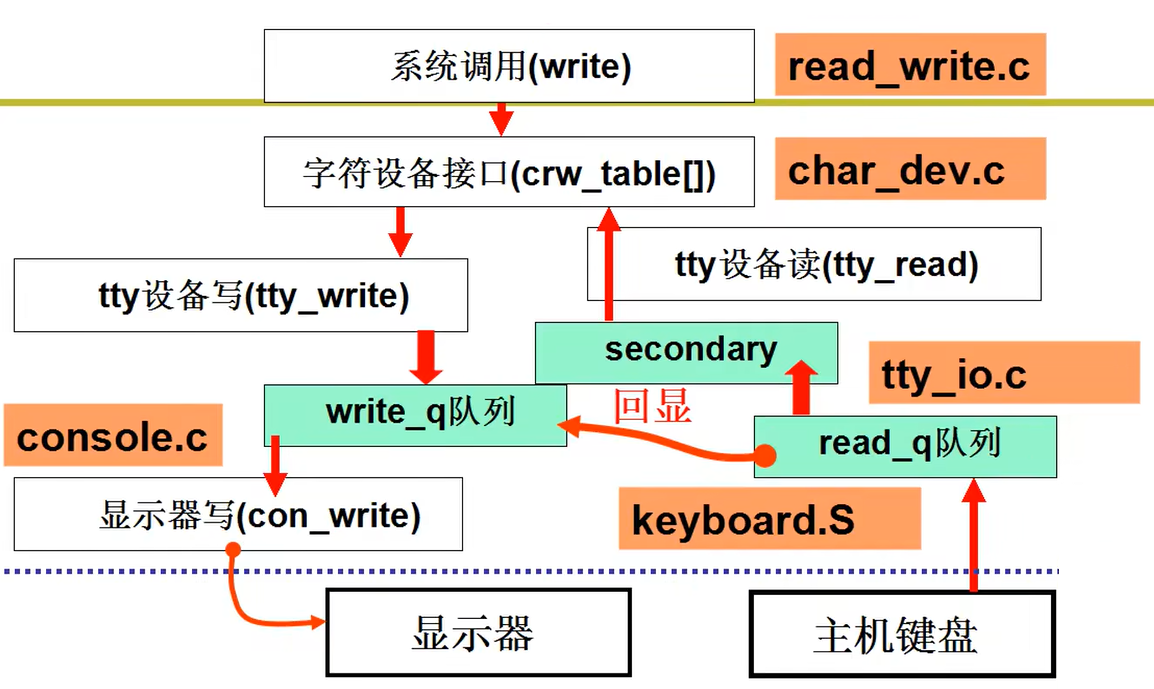
进程
在cpu运行时我们知道对IO操作的执行往往比计算要慢很多,可以达到1000000:1;若是使用单一的运行方式操作大量IO,cpu的利用率非常低;为了提高cpu的利用率同时防止一个应用程序被一直等待,我们就引入了进程和多进程。而操作系统的最本质工作就是对进程进行管理。
使用进程可以在宏观上实现并发,加强资源分配和隔离。
在操作系统中我们使用PCB(进程控制块)来管理一个进程。进程的运行是有多种状态:
对于PCB的操作,是操作系统的核心;多进程的切换就是对PCB进行读写,同时搭配对应的寄存器。
对于多进程的切换还要考虑使用的进程调度算法和进程同步。
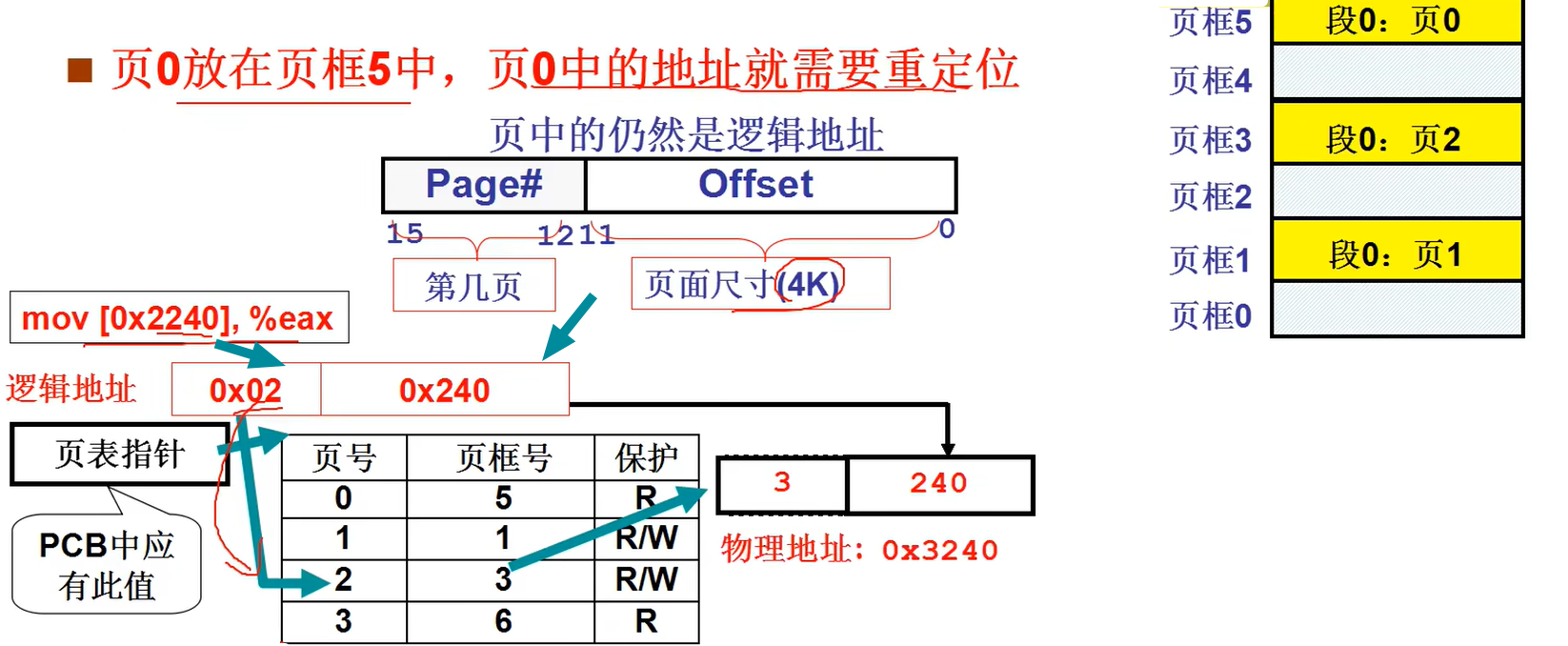
除此之外进程之间为了方便开发和移植,防止不同进程访问了同一内存,引进了地址映射。
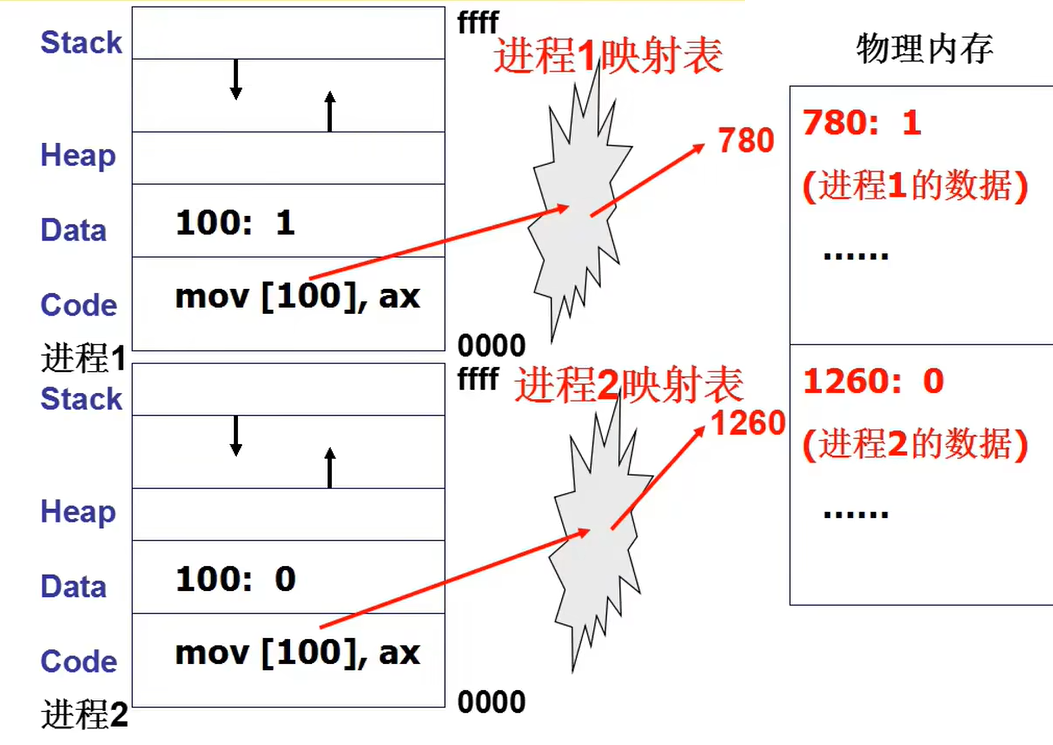
具体的内存空间切换在内存管理中展开,在这里主要将PCB的操作和栈的切换(就是线程)。
线程
线程的产生一方面是为了减小进程切换的开销,同时也是并发工作间的数据通讯变得方便。
为什么会有上面的优点呢?这就要看多线程和多进程之间的区别了。
多线程之间会使用共同的内存空间(在Linux中线程共享:代码段, 堆区, 全局数据区, 文件描述符表)这使通信变得非常方便,可以直接相互访问数据;而多进程则相互独立。
当然为了实现线程间的切换就必须有独立的栈和寄存器数据。
分类
用户级线程
用户线程是完全由用户管理的线程库。用户线程的创建、调度、同步和销毁全由用户完成,不需要操作系统内核的参与,因此这种线程的系统资源消耗低且高效。但同时若发生阻塞就会阻塞整个进程,因为在操作系统眼中其是单线程,也因此不能使用CPU的多核优势。
这和协程有点类似。
内核级线程
顾名思义,内核级线程就是通过内核和硬件来实现线程;这能良好发挥多核的优势。
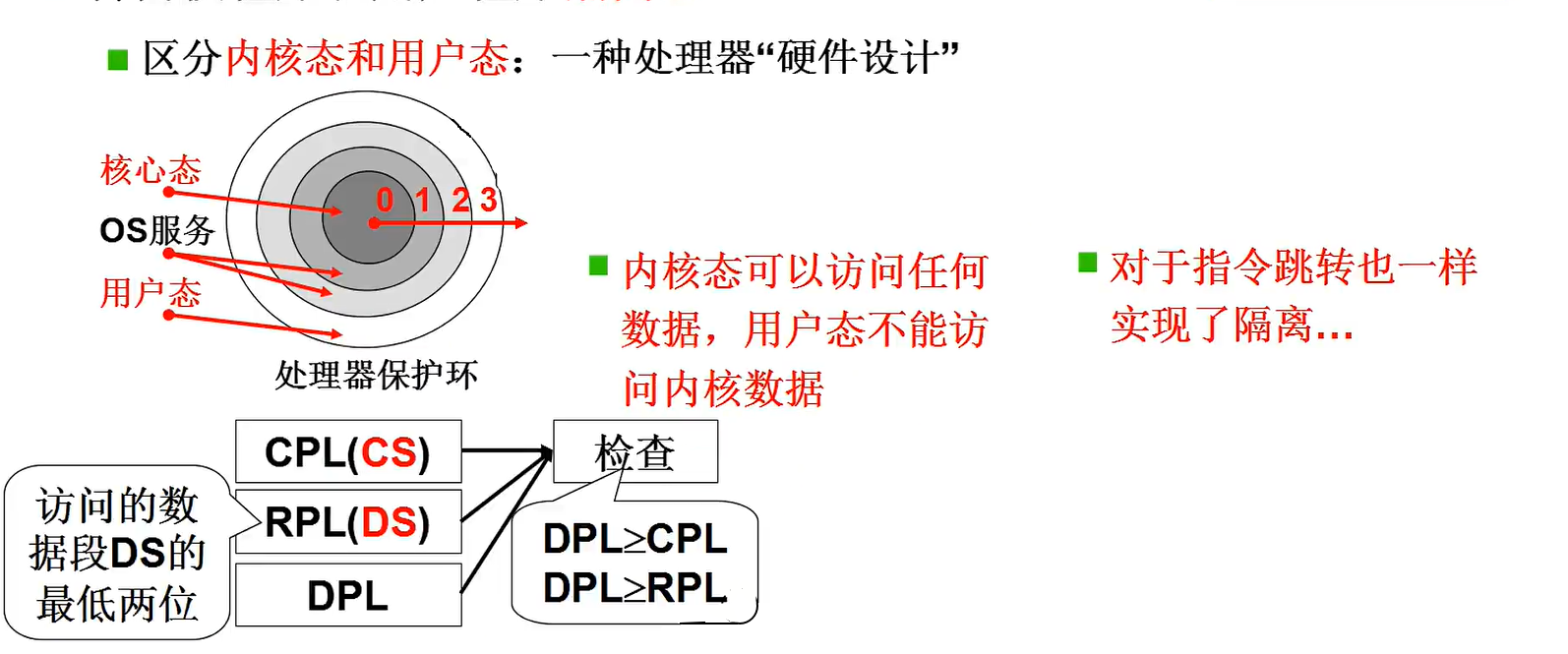
如果说用户级线程管理了2个栈(选择执行线程的栈和将要执行线程的栈),那么内核级的线程就是管理了2套栈(用户态的栈和内核态的栈)。
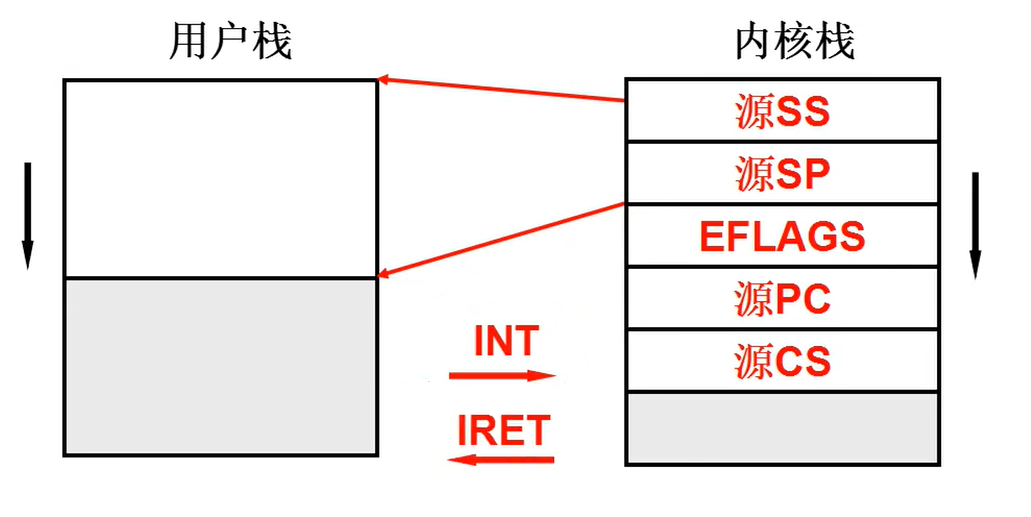
因为要通过内核实现,因此会要使用中断进入内核,这时会将用户栈的信息压入内核栈(因为内核也要用栈,同时分开有利于保护资源),而退出时又会恢复用户栈。这时会发现,用户栈和内核栈已经关联在了一起,因此内核级线程的切换只要切换对应线程的内核栈即可。
简单总结:通过中断和手动将当前用户信息压入内核栈,更换内核栈,
手动和中断返回恢复寄存器和用户栈(已经是另一个线程了)。
调度
上面讲解了如何切换,现在就是为了解决选择哪一个就绪态的任务来切换。
在操作系统中调度主要看的是响应时间和周转时间。两者刚好相反,响应时间小了,系统切换的就频繁,周转时间就大;周转时间小了,响应时间就大;这需要一个合理的比例。
前台任务关注响应时间,后台任务关注周转时间。所以前台和IO任务一般比后台和cpu任务优先级高。
常见的的调度算法
FCFS
使用FIFO,先到的先执行。
SJF
在上一种的基础上,让执行短的任务先做;虽然总体时间是一样的,但由于短的任务可以很快完成,使完成满意度提高。这也就是使用了优先级调度。
轮转调度 RR
使用时间片调度任务,每过固定时间切换一下 。因此时间片的取值是重点,太大会使响应时间太大,太小会使周转时间太大。
时间片一般为10-100ms,切换时间0.1-1ms(1%)。
优先级
根据优先级划分多个列表,在列表内使用轮转调度。如freertos就是使用这种调度。
这种虽然非常不错了,但还是有一定的缺陷:若高优先级任务一直插入,低优先级的永远也执行不了,这既是优点也是缺点。
Linux0.11中的方法
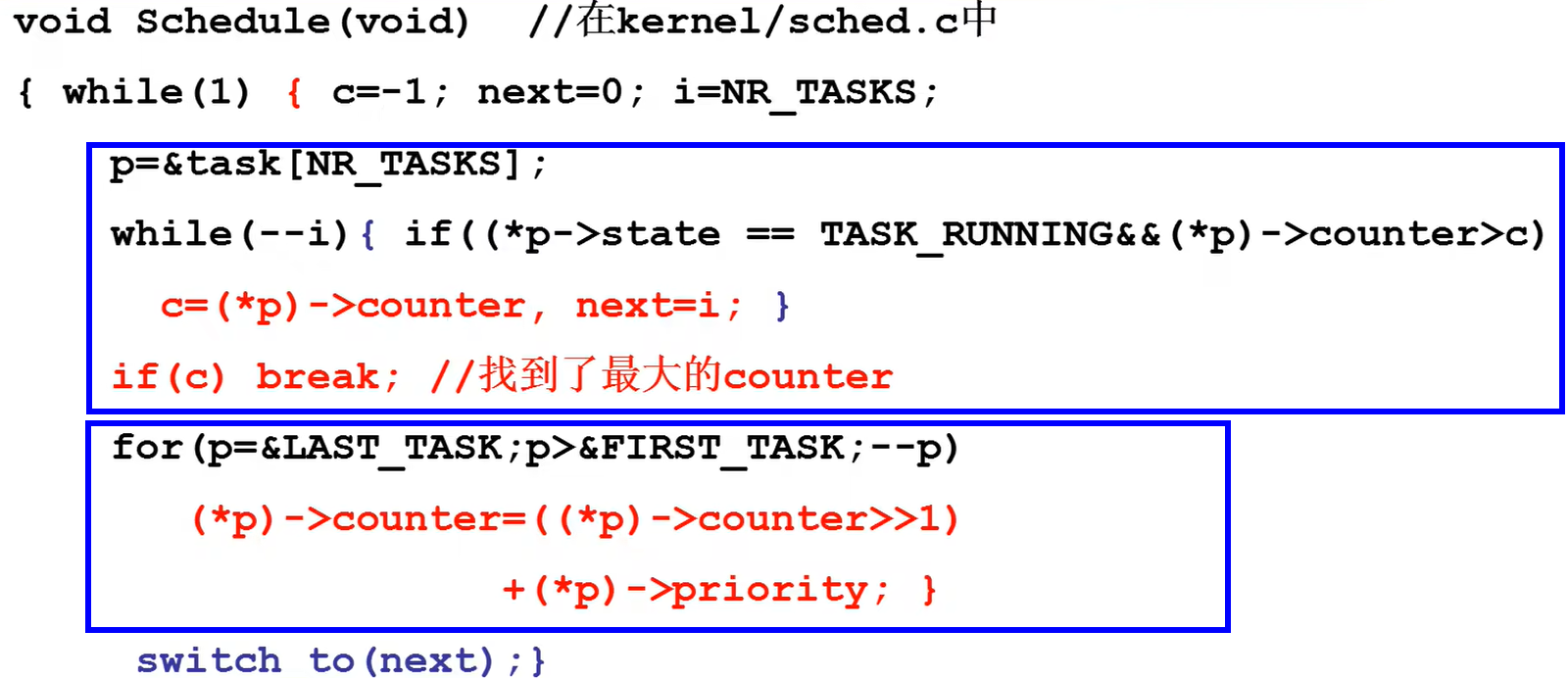
如上图中,linux0.11中使用了一个数组来存放PCB,使用了counter来表示优先级和运行时间片长度。
第一个方框中是为了找出优先级最高的就绪态任务,这样确保了响应速度。
第二个方框中表示如果所有就绪态任务的时间片都用完了那么再一次初始化。这样子做确保了低优先级的任务也可以执行。
那么为什么要右移呢?这实现了动态优先级,可以让那些阻塞的任务恢复后有高优先级这样可以更快的响应。
为什么右移?这使得时间片符合公式:$counter+\frac{1}{2}counter+\frac{1}{4}counter+\frac{1}{8}counter+...\le2counter$。这使得
counter不会变大无限大。
counter在表示优先级的同时也是运行的时间片长度,这使得其在时间中断中会不断减小,直到为0后再一次进行调度切换。如下图:

使用这种方法来调度很好的平衡了响应和切换,一个进程只要一个conunter开销小。
信号量
除了调度,还有一个重点就是同步问题。最简单的方法就是进程间有一个flag来标志,但这只能表示有没有,不能解决有多少,因此引入了信号量。
信号量的核心是一个整数n,当其大于0时,表示还有n个资源;当其小于等于0时,表示还有-n个等待资源的进程。
除此之外还应该有一个队列,来记录等待的进程。
同时可以发现当信号量的整数取值只有1和0时,可以实现互斥来保护临界资源,这就是互斥信号量。
临界区保护
当然上面是信号量的核心,但没有临界区保护,信号量也无法工作。同时这个临界区要满足互斥进入,有空让进(无锁能加锁),有限等待(所有想加锁的都在一定时间后能加锁)。
临界区保护有多种方法,我们先看只有两个进程的算法:
-
轮换法
使用一个turn,turn为1是a进程进入临界区,为0是b进程进入临界区,a退出时将turn置为0,b退出时将turn置为1。
缺点:假如现在turn为0,但b无需进入临界区,a要却被阻塞。不满足有空让进。
-
标记法
使用一组flag,各个进程对应一个flag,一个进程进入临界区会标记其flag,其他进程根据这个flag阻塞。
缺点:在a进程flag标记的同时,b进程也进行了标记,导致二者进入僵持状态。不满足有空让进。
-
Peterson算法
将以上两个算法结合就能良好的解决各自缺点。

在flag的基础上加上turn,当进入僵持时就会因为turn总有一个进程去执行,从而打破僵持。
面包店算法
这时将Peterson算法拓展,就有了支持多进程的纯软件的面包店算法。
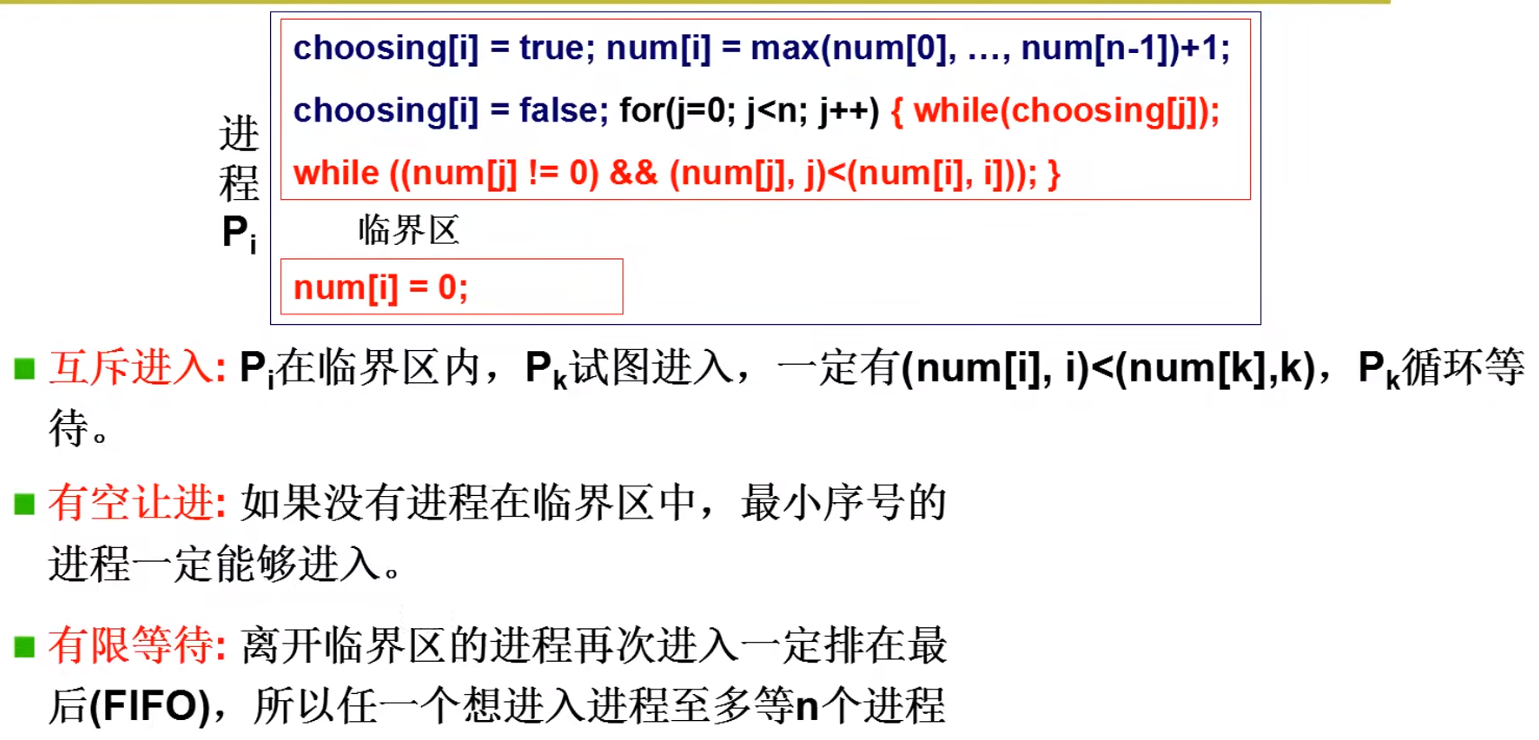
在上图中num既充当Peterson算法的flag,为0表示false退出临界区,大于0表示true要进入临界区。
同时num又是Peterson算法的turn,不过有所改进,每个进程每次进入都会取已等待进程中num的最大值加一,之后num最小的在等待的进程一定可以进入临界区防止僵持。
这个算法虽然非常好只要软件就能实现,但存在num最大值查找开销大,num取值可能溢出的问题。
关中断
为了解决上面纯软件的问题,是否可以使用硬件配合。
最简单的方法就是关中断,问题的产生就是因为中断(时间,系统调用切换)产生的任务切换,只要将中断关闭不就可以解决。
但这主要针对单核心CPU,当多核心CPU时会比较麻烦。
硬件原子指令
硬件支持修改一个变量可以一步完成,不会发生切换。这时只要判断这一个变量flag的真假就好。
死锁
当有多个信号量时,就容易发生死锁,那么如何预防和恢复呢?
-
破坏死锁条件:一次性申请所有资源,按顺序申请资源。
缺点:浪费资源。
-
死锁避免:每次资源请求后,若发生死锁(银行家算法),驳回。
缺点:算法是O(mn^2^),开销大。
-
死锁检测:定期检查,发现死锁就让其中一个进程回滚。
缺点:回滚复杂。
-
死锁忽略:忽略不重要的死锁,重启,开销小。