内存的使用和分段
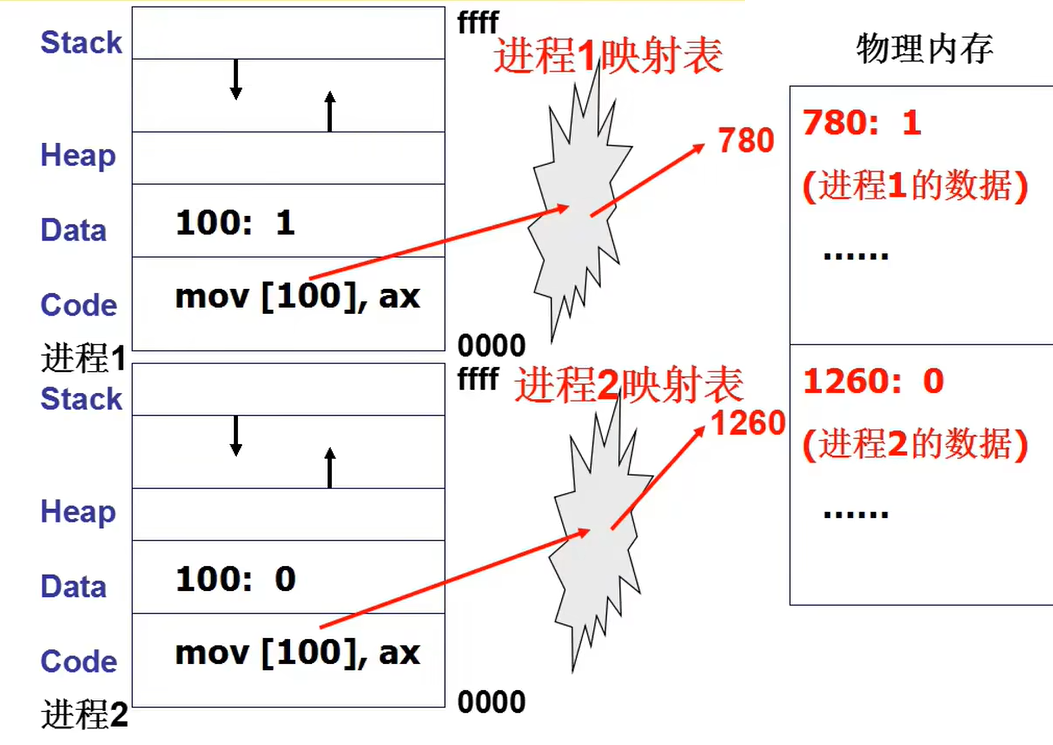
多进程因为切换和阻塞,常常会改变实际地址,因此要有一种良好的寻址方式。
写程序时的内存地址有直接写实际地址,这常在嵌入式系统中使用。但在操作系统的环境中过于复杂,这样容易出问题。
因此我们使用逻辑地址,这方便我们写程序,但在实际内存中的地址应该如何得到呢?
一种方法是使用编译时重定位,但这也要在编译时知道空的内存空间,实现使用时和写实际地址差不多。
还有就是使用在载入时重定位,这给虽然解决了上面缺点,但载入后就无法改变了,只有第一次是动态加载,无法实时动态加载。
因此最好的方法是在运行时重定位,寻址方式:PCB中保存的基地址+逻辑地址。
既然使用了运行时重定位,那么不如将进程(程序)分段(编译时),如:
| 程序: | 代码段 | 变量段 | 函数库 | 栈 | 堆 |
|---|
这样子将进程(程序)分段,增加了内存的灵活性和利用率,方便根据每个段的特性进行管理。
这时的寻址方式就变为:段基址+段内偏移。而PCB中就要记录各个段的基址——进程段表LDT(一般使用硬件寄存器LDTR配合载入段基址)。
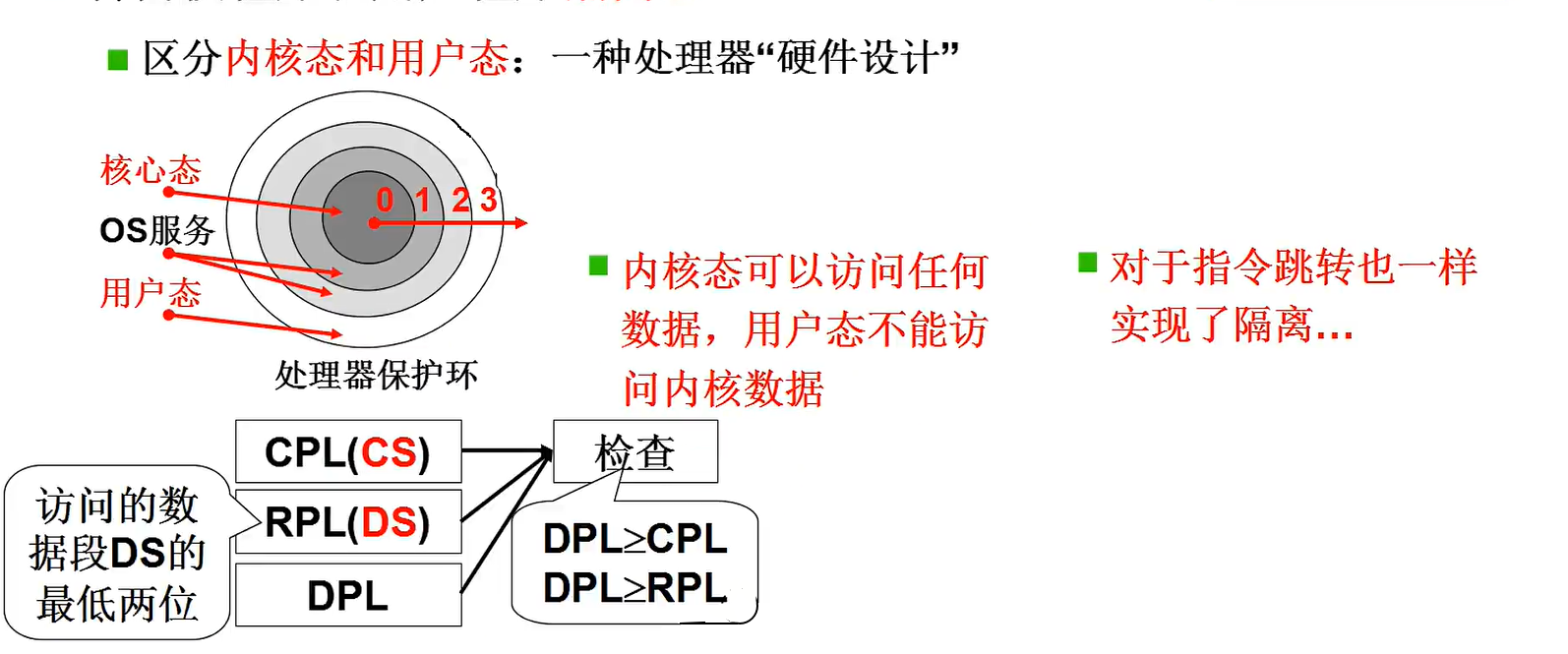
LDT和GDT表是类似的,只不过GDT是整一个操作系统的表。GDT是操作系统的段表,LDT是每个进程的段表。
内存分区和分页
上面介绍了内存的使用,那么在使用之前就要确定,哪块内存是可以用的,这就需要内存管理了。
借鉴上面,管理的最好就是分区管理;最简单的管理方法就是固定分区,但这不灵活更不高效;因此需要采用动态分区。
动态分区内存管理不仅仅要能动态分配内存,并有记录使用情况的表,还有有释放内存的功能。
同时分配方法还多种多样:
- 首先适配:使用第一个找到的适配分区。(速度快)
- 最佳适配:最接近需求的分区。(内存碎片)
- 最差适配:最大的分区。(大分区数量少)
以上方法各有优点,但内存效率都比较一般,因此引出了分页,来解决内存分区导致的内存效率问题。
页就是将区在变小(如在linux0.11中4KB为1页)。虽然每页存在没用完的情况,但非常小(如在linux0.11中一定小于4KB),而分区可能会比较大。
同时我们将进程(程序)的分段再分为页存储,因此段表LGT要搭配逻辑页表和相关硬件(MMU内存管理单元和相关寄存器CR3)。页表是连续的即使中间某一页没有使用,这样可以是查找直接使用下面的方法:
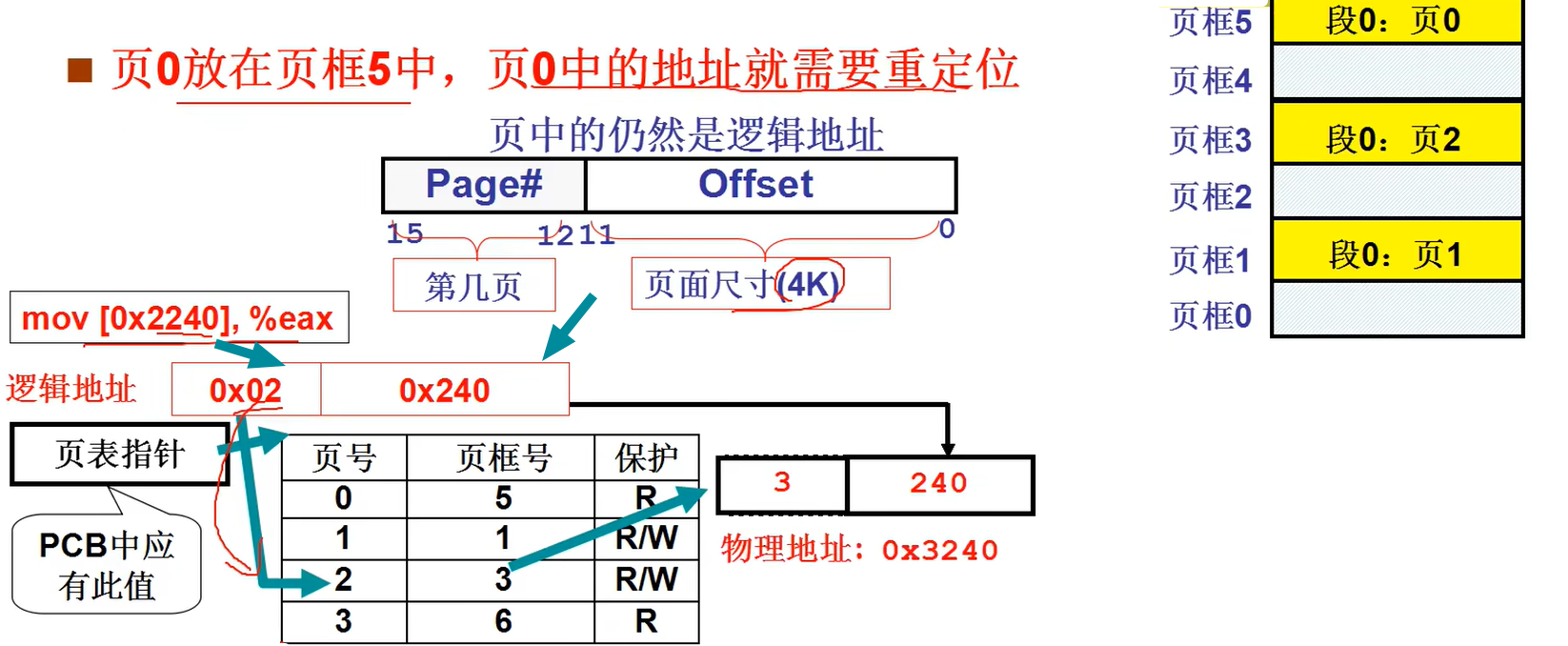
总结上面内容就是:一个进程(程序)会被分为许多段,段又拆分为页。程序员访问该进程(程序)内存会访问段LDT,再通过段中页表访问实际地址。而实际内存是通过分页的内存映射表来管理内存。
多级页表和快表
分页虽然良好的解决了内存碎片,但分页后逻辑页表多又不能将没用的页表省去,这些表(主要是每个进程(程序)都有页表)就占用了不少空间(假设1个进程要10M页表,10个进程就要100M来存储了),为此有了多级页表,将页表占用空间减小。
多级页表,就好像目录。将内存分为多级页表,那些没用使用的内存,只要前几级页表就不再进行展开;而使用的内存就好像目录结果一样,一级一级展开。
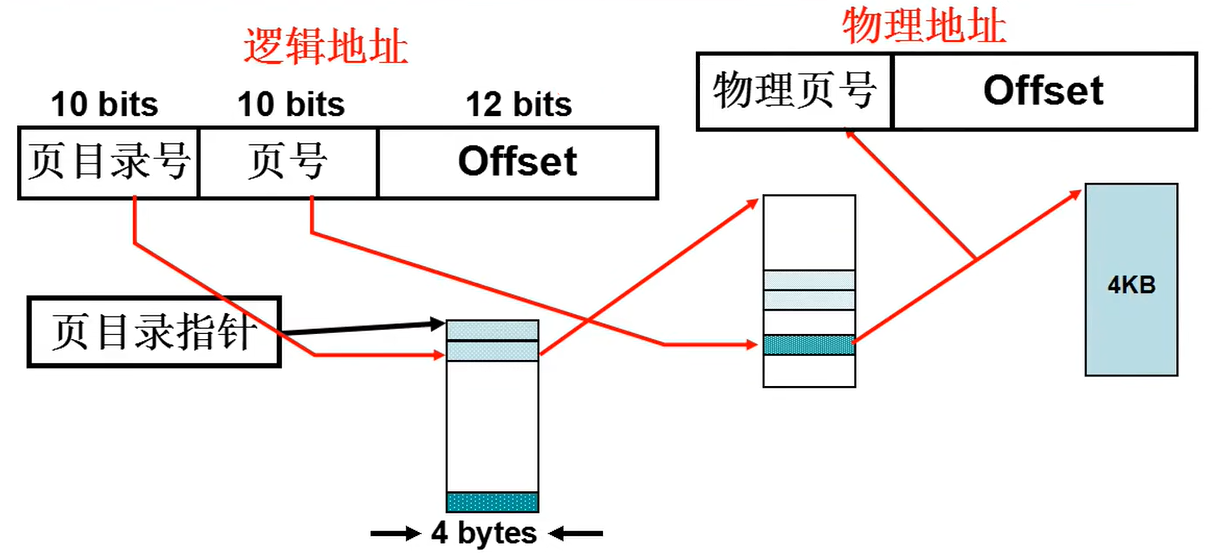
假设使用32位的地址的4GB内存空间,如果使用简单的分页,那么就需要1MB4(一个表项大小)=4MB空间。而假设如上图的多级分页,其中要用目录的3个项,那么一个表有1KB\4=4KB,一共有4个表(1个目录+3个页表)就是16KB,远小于4MB。
虽然良好的解决了内存问题,但也增加了访问速度(还是比不连续页表(折半查找)要快)。
为了提高多级页表的查找速度,就引入了快表。
多级分页像目录,那么快表就好像书签索引,记录了常用和最近使用的页号。
快表一般和硬件联合,使用寄存器组TLB一组相联快速存储(类比cache和主存)。
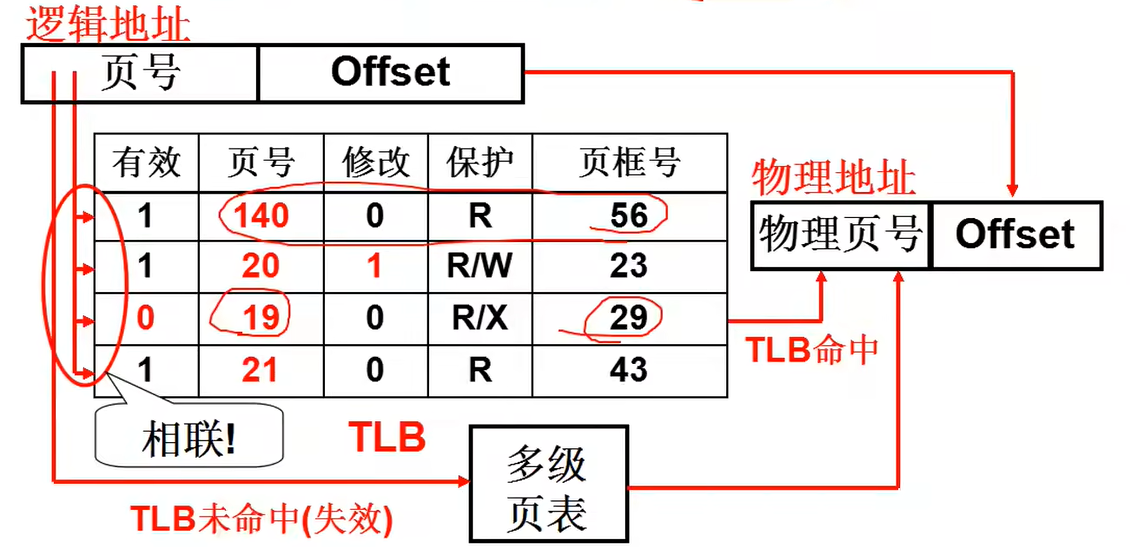
由于TLB是寄存器,所以其大小一般在[64,1024]KB。
内存管理
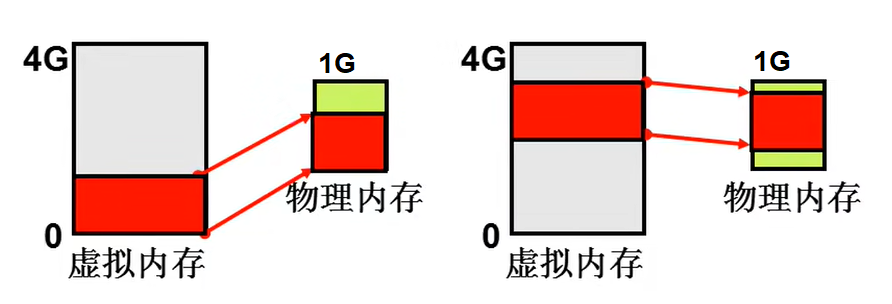
上面的人和应用希望用段,而物理内存希望用页,因此就将两种结合,段面向用户,页面向硬件。
从应用程序出发来看,程序的各个段需要地址,而这个段地址的虚拟的,要通过页来映射真实地址,我们将这个段地址的内存称为虚拟内存。
所以当用户访问内存时,先用段表映射地址得到虚拟内存地址,再通过虚拟地址根据页表映射得到物理地址。
因此虚拟内存就是操作系统将一个值给LDT,并没有真实地址。
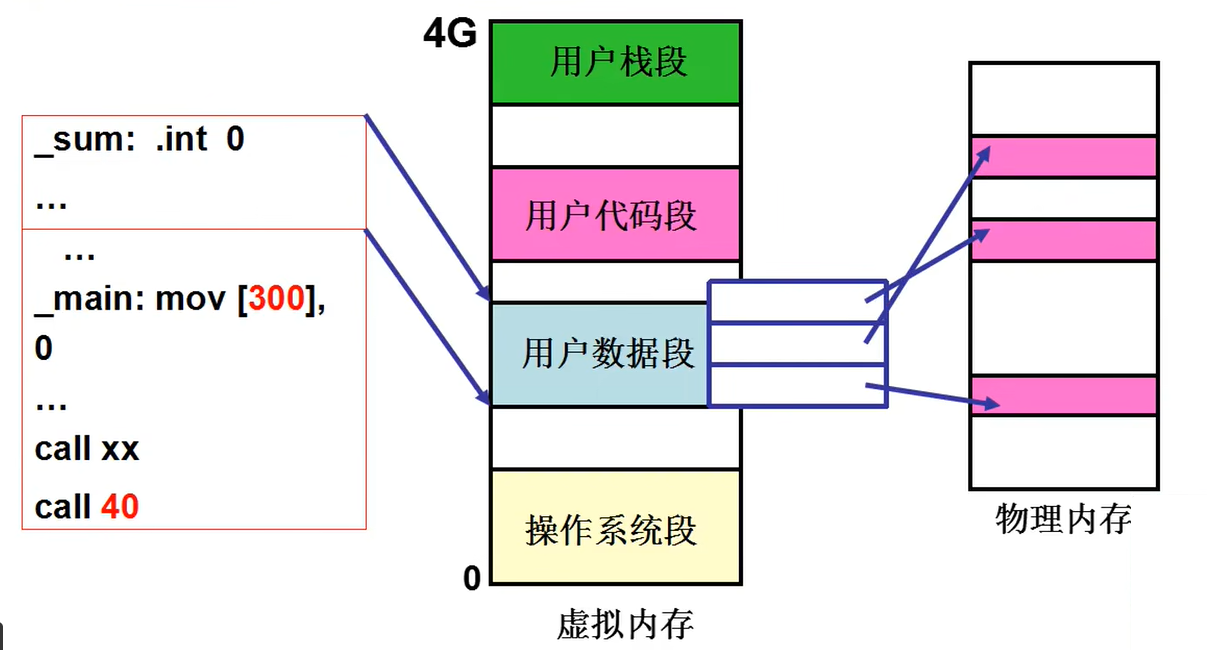
建立映射这里以fork函数流程举例:首先就是要分配虚拟内存给新进程LDT,然后就是分配内存建立新进程的页表。
下图是多进程访问内存:
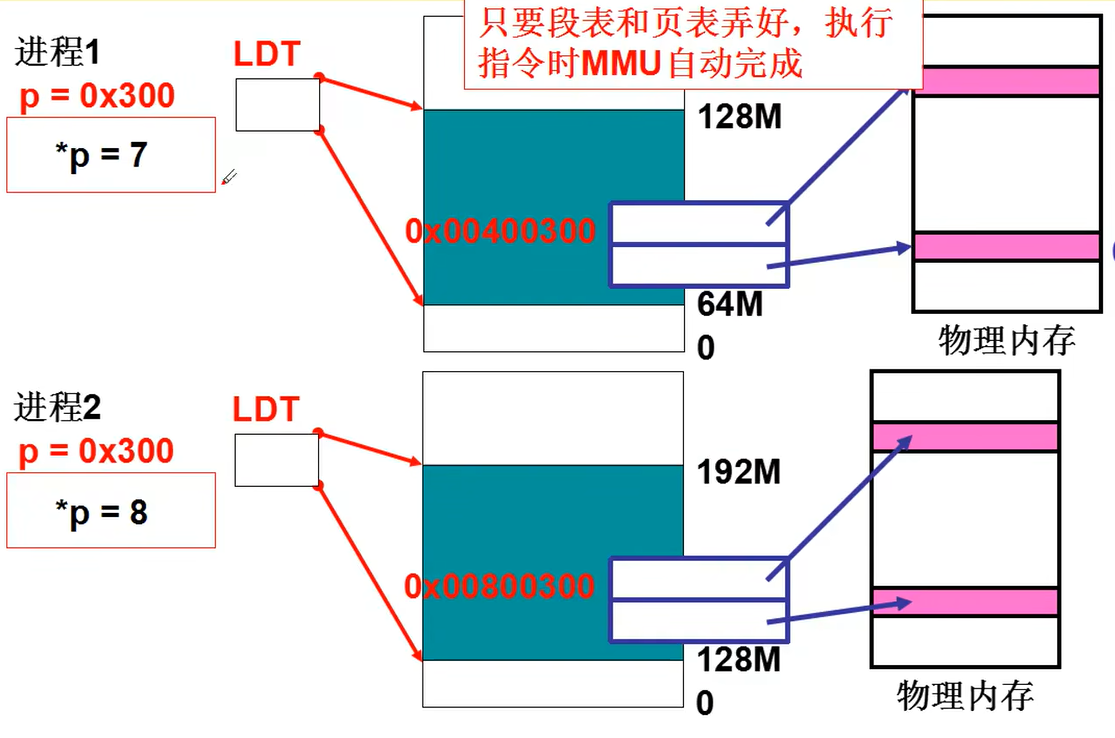
有了虚拟内存,能使用户就不需要时刻操心实际的物理情况,同时通过内存的换入和换出可以实现小内存变“大内存”。
内存换入
当通过映射发现当前访问的页不在页表中,就会产生中断调页。
采用请求调页而不是请求调段,原因是什么 ?请求调页的粒度更细,更能提高内存效率.
再中断中申请一个空闲页,从磁盘读入数据,建立两者映射。
内存换出
上面的中断中申请空闲页时并不能总是获得新的页,因为内存是有限的,所以要有换出操作。
换出主要就是算法的选择。假设页表一共有3个页框,页的读取顺序是ABCABDADBC。
FIFO
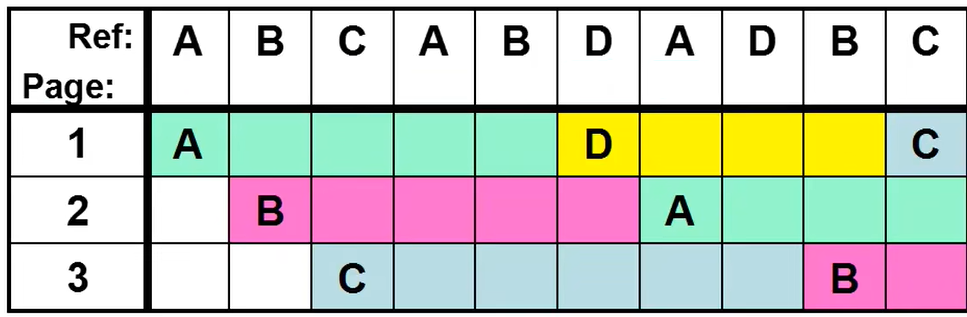
采用先进先出的方式时,按上面的读取顺序,一个产生了7次换入换出。
MIN
选择将来最远才会再次使用的页淘汰。淘汰将来最远使用。
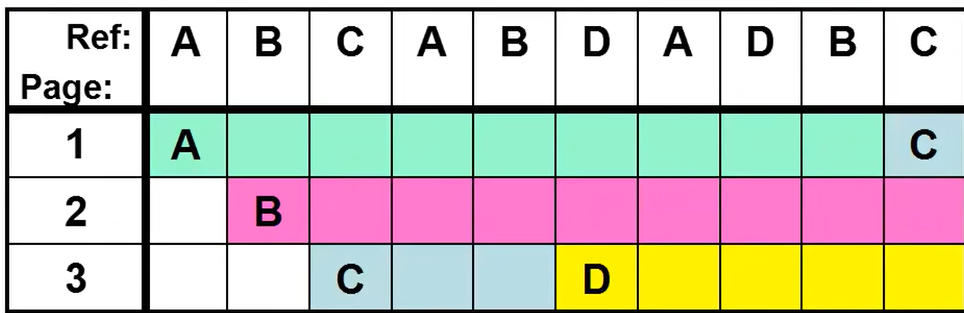
这时只有5次换入换出。但是我们怎么能知道将来发生什么呢?
LRU
既然用MIN我们不知道未来,那么根据代码的局部性,我们不如用历史来预测未来。淘汰最近最少使用。
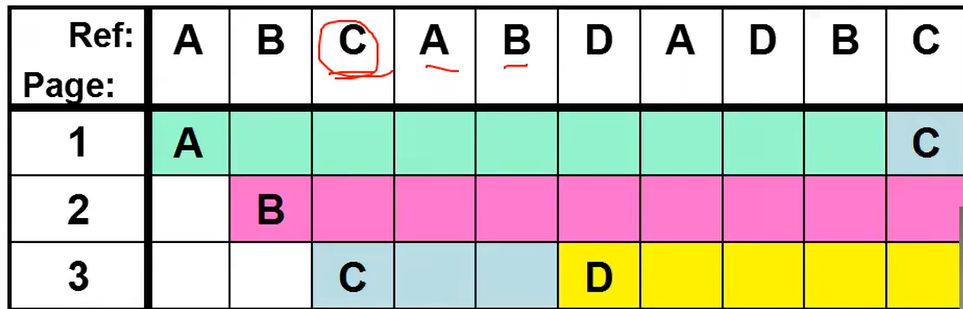
在这个例子中基本和MIN的效果差不多。
那么如何获取使用情况呢:
-
时间戳:将最近一次使用的时间记录下来。
缺点:每次执行一条指令都要更改,代价太大。
-
页码栈:一个只有页表项个数(如上面就要3个)的栈,每次将使用和栈顶的页不同的页就压栈,栈如果是满的就丢弃栈底并下移一个,这时栈底是最不常用,栈顶反之。
缺点:和上面差不多
Clock
这时我们发现LRU完整的实现有点困难,因此将其简化为Clock算法,不再使用最近最少使用而是最近没有使用:
每个页有一个引用位,每次访问时硬件会将改为置1,要选择淘汰时,扫描改为,是1的重新置0,是0的淘汰。
这同样会产生一个问题,当缺页很少是,所有引用位都是1,这时会将所有1变成0,再将第一个变0的替换,不就变成了一种FIFO算法。
为了改善这一个问题,就需要定时间的将dshi所有引用位置0,这样能真正实现找出最近没有使用的。
这时定时置0就像分针,而缺页换出就像时针。
页框分配问题
上面的换入和换出都将调页,那么页表到底有多少页框(也叫做帧)比较好呢?分的多消耗资源,分的少就反复调页CPU利用率低。这时要用工作集算法(一种动态页面替换算法,前面的是静态的)。