
起源——ASCII
计算机是美国首先发明。
为了将需要的可见字符(数字,标点符号,英文字母)和控制字符在计算机中进行存储运用,美国人将这些字符(128个,95个可见字符,33个控制字符)进行了编码,于是有了ASCII字符集;并且为了方便对照存储,他们直接将字符对应的码位转化为二进制存储(ASCII码)。
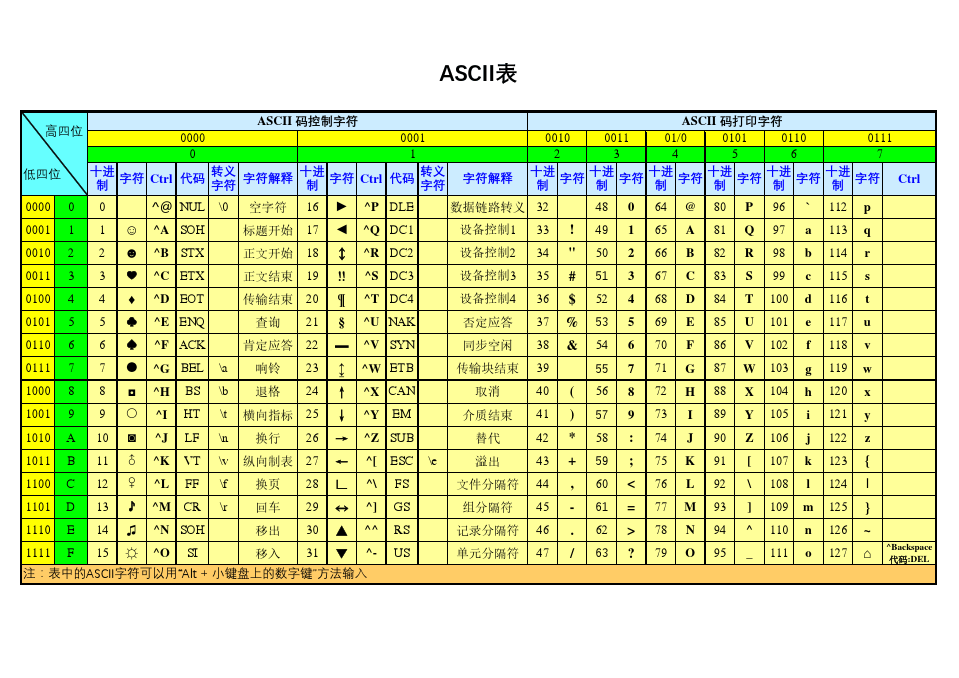

发展1——拓展ASCII
因为美国开始时就在本国使用计算机,所以表示128个字符的ASCII码完全够用。但随着计算机开始被欧洲国家使用,128个字符就不够用了。
因此他们对原有的ASCII就行了扩展:将原有的ASCII的开头位由0改为了1,从而使128个字符拓展到256个字符,解决了欧洲国家的计算机编码问题。
发展2——GB2312
虽然拓展ASCII码解决了欧洲国家的问题,但当计算机来到中国时,那怕256个码位全放汉字,也是远远不够。
为此我们设计将1个字节,扩展为2个字节(用16位来表示一个字符)。同时我们采用分区管理(方便查找管理),将8836个码位,分为94个区,每个区含94个码。其中1-9区收录了除汉字以外的682个字符;10-15和88-94区为空白区,没有使用;16-55取收录了3755个一级汉字,按拼音排序;56-87区收录了3008个二级汉字,并以部首和笔画排序。

这就是GB2312字符集。该字符集的码位由区号+行数+列数组成四位数。在存储时,我们将码位一分为二,分别转化为十六进制并加上A0,将最终得到的值组合,便可得到相应的GB2312码。
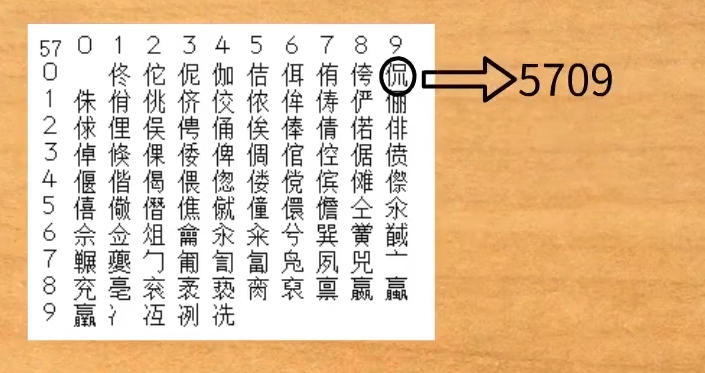
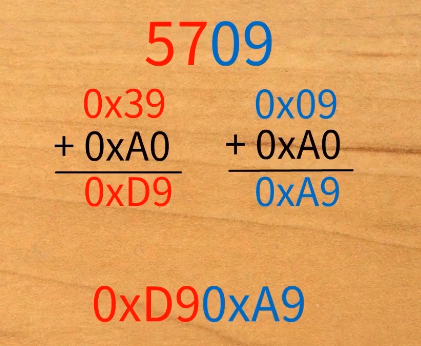
猜测:加A0使GB2312码的高八位和低八位都大于127,方便区分、兼容ASCII码。
发展3——GBK,GB18030
GBK
尽管GB2312已经收录了6763个汉字,但汉字太多了,还是有点不够。所以我们有对其进行了扩充:将之前一些没有使用的码位都用上,并且只规定其高位要大于127。以此新增了近20000个汉字和符号,发明了GBK字符集。
GB18030
但后来我国少数民族也有字符要存储,于是我们在GBK的基础上有新增了几千个少数民族的字符,对应就有了GB18030字符集。
发展4——Unicode2.0
以上两次发展是我国对我国字符的存储。既然我们中国可以这样子做,那么其他国家也可以。因此会导致每一个国家有自己的字符编码,那么就会导致不同国家之间出现乱码、交流不便。
这时ISO(国际标准化组织)和 统一码联盟看不下去了,于是提出了Unicode2.0的标准来规范。Unicode的目标很简单:把世界上所有的字符都标号编码。
UCS-2
Unicode一开始使用UCS-2字符集。它将所有的字符罗列到一起并标上码位,然后直接转化为二进制。 一共两个字节,可以表示65536个字节。
UCS-4
之后慢慢人们发现UCS-2还是不够表示世界上的所有字符。于是就又有了UCS-4。它由4个字节(32位)组成,可以表达将近43亿字符。但实际上会用20多亿个编码空间,且使用范围并不超过0x10FFFF。
虽然USC-4涵盖得非常全面,但不是所有国家都非常乐意接受,因为其所需存储空间较大,就比如ASCII码要扩大四倍。
UTF-8
标准
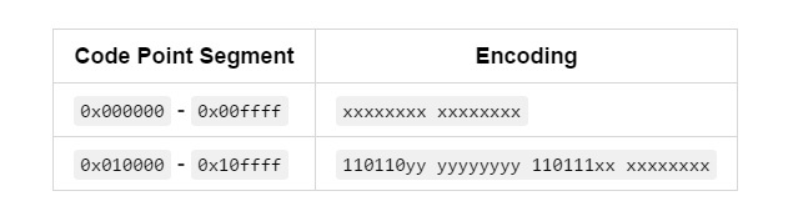
UTF-8每次传八位数据,是一种可变长的编码格式。它将UCS-4码位划分为四个区间
- 0x 0000 0000 至0x0000 007F :
0xxxxxxx - 0x 0000 0080 至0x0000 07FF :
110xxxxx 10xxxxxx - 0x 0000 0800 至0x0000 FFFF :
1110xxxx 10xxxxxx 10xxxxxx - 0x 0001 0000 至0x0010 FFFF :
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
例如:王在UCS-4中码位为0x0000 738B,属于第3区间。
将码位转化为二进制:0000 0000 0000 0000 0111 0011 1000 1011
去掉所有的0000,带入对应格式,得到其UTF-8的码位是:1100111 10001110 10001011,也就是十六进制的0xe7 8e 8b。
UTF-8是目前最主流的字符编码!
带bom
Windows就是使用BOM来标记文本文件的编码方式的,但utf-8建议不要用bom。
BOM:在UCS编码中有叫做"ZERO WIDTH NO-BREAK SPACE"(零宽度无间断空间)的字符,它在UCS中是不不能再的字符(即不可见),它是插入到以UTF-8、UTF16或UTF-32编码Unicode文件开头的特殊标记,用来识别Unicode文件的编码类型。
但在现今的绝大多数编辑器中都看不到BOM字符,因为它们能理解Unicode,所以去掉了读取器看不到的题头信息。
下表列出了不同编码所对应的BOM。
BOM Encoding
EF BB BF UTF-8
FE FF UTF-16 (big-endian)
FF FE UTF-16 (little-endian)
00 00 FE FF UTF-32 (big-endian)
FF FE 00 00 UTF-32 (little-endian)
UTF-16
这也是对UCS-2的一个扩展版,相较于UCS-4的完全扩展为32位。UTF-16对原有的UCS-2不做改变用16位,而对那些要加入的新字符则采用32位。
种类
“ABC”这三个字符用各种方式编码后的结果如下:
| 类型 | 码位 |
|---|---|
| UTF-16BE | 00 41 00 42 00 43 |
| UTF-16LE | 41 00 42 00 43 00 |
| UTF-16(不带BOM) | 00 41 00 42 00 43 |
| UTF-16(Big Endian) | FE FF 00 41 00 42 00 43 |
| UTF-16(Little Endian) | FF FE 41 00 42 00 43 00 |
UTF-16BE
BE即大端模式(Big Endian),低地址存放最高有效字节(MSB):地址的增长顺序与值的增长顺序相反,也就是地址由小向大增加,而数据从高位往低位放。
UTF-16LE
LE即小端模式(Little Endian),这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
UTF-32
人们使用UCS-2发现不够,而用UCS-4又太多了,于是就有了UTF-32。UTF-32和UCS-4的关系与UTF-16和UCS-2的关系有点相似。UTF-32的编码值与UCS-4相同,只不过其编码空间被限定在了0~0x10FFFF之间,可以说:UTF-32是UCS-4的一个子集。
UTF-32的种类可以参考UTF-16,还是以“ABC”这三个字符举例:
| 类型 | 码位 |
|---|---|
| UTF-32BE | 00 00 00 41 00 00 00 42 00 00 00 43 |
| UTF-32LE | 41 00 00 00 42 00 00 00 43 00 00 00 |
| UTF-32(不带BOM) | 00 00 00 41 00 00 00 42 00 00 00 43 |
| UTF-32(Big Endian) | 00 00 FE FF 00 00 00 41 00 00 00 42 00 00 00 43 |
| UTF-32(Little Endian) | FF FE 00 00 41 00 00 00 42 00 00 00 43 00 00 00 |
参考:







